Projects
Connectome
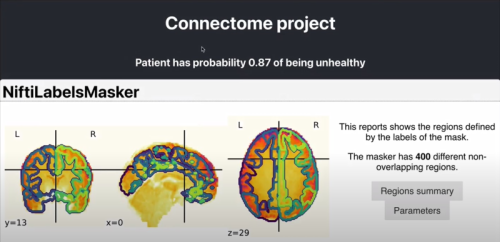
The Connectome project aims to provide a platform for medical practitioners to detect disconnectivity in individual patient connectomes and predict the probability of a neurological disorder. The prototype creates connectivity matrices from fMRI images via Schaefer2018_Parcellations atlas, trains a graph convolutional network on UK Biobank data and encodes the image to an embedding space. A prototype binary classifier is implemented to detect anomalous connectomes (to be trained further). Results can be evaluated with a probability of anomalous connectome as well as visualizations of brain region connectivity and the patients' connectivity matrix. The project also includes a front-end and back-end so it can be easily web-hosted.
Adea
Due to a lack of the information about the entire production chain of cultured meat, lack of flexibility and interactivity, lack of statistical tools that provide a good entry point for interested people and lack of cross-country comparison of the industry, the project team created – under the supervision of the project partners Katharina Brenner and Manuel Bauder (Adea Biotech) – a web application that uses an open-source data set from GFI to solve these problems. This web application allows the users to have an overview of the cultured meat market which includes statistical plots, the distribution of cultured meat companies worldwide, and the distribution of cultured meat companies in the cultured meat value chain. As partnerships across the value chain play an important role in this new industry, this web app helps its users to find potential partners/collaborators.
Wildfire Propagation
In this collaboration with ororatech, the students worked on building CNN-based methods to predict future spread of wildfires. Besides the previous fire masks, multiple additional satellite data sources were integrated, providing, e.g., weather data, landcover types, and elevation information.
Ambulance
Reducing the time that an ambulance needs to arrive at an incidents can save lives. Dynamically redeploying ambulances to different basestations thus can save lives. The students worked on implementing a discrete event based simulation that replays real-world incidents, processed multiple incident datasets and implemented existing baselines. In order to redeploy ambulances predicting the future demand plays a vital roll. Therefore, students evaluated and implemented various ambulance demand prediction models.
Schafkopf
Schafkopf is a traditional Bavarian card game that has complex interaction with other team members (ad-hoc teamplay). The students worked on implementing a high-performance c++ simulator and implemented various agents ranging from rule-based, monte-carlo tree search, to reinforcement learning based agents.
Connectome
Together with the project partner Dr. med. Boris Rauchmann (LMU Klinikum), the Connectome team explored the prediction of Alzheimer’s disease diagnosis based on connectivity matrices utilizing the Brainnetome Atlas. The results of the project include a pipeline for processing connectivity matrices to predict and explain a patient’s Alzheimer’s status. The pipeline allows users to automate the training, evaluation, and interpretation of various models based on several dataset options, such as aggregated connectivity matrices or graph metrics applied to the human brain connectivity data.
Gather
In this project, the students were confronted with the problem of completing the road network of Antananarivo, Madagascar, to close sanitation gaps. The project was conducted in collaboration with Gather, a registered charity. First, the quality of existing digital maps, i.e. Sentinel-2, Google Maps and Mapbox was assessed and Mapbox was chosen as the most comprehensive available data source. Secondly, road segmentation models (U-net architectures) on aerial imagery to detect routes that have not been digitized yet, were implemented and compared.

Convincingness of Emotional Argumentation
In this project, students applied techniques from Emotion Mining on Datasets from the Argument Mining area. Students implemented a pipeline for automatic identification of emotions in arguments and demonstrated empirically the role of pathos in the arguing process.
Partially Observable Travelling Officer Problem
This team tried to extend a single-agent travelling officer to multiple agents and partial observability (settings where a full sensor network is not available)
KDD Cup 2021: City Brain Challenge
This team tried to manage traffic lights on a large scale to optimize traffic in cities.
Multitask learning for space weather
In this project, which is a cooperation with GFZ, the students work on creating a spatio-temporal model of space weather. In particular, we combine measurements of solar activity measured by satellites and on earth, and geomagnetic activities, and aim to predict several shape parameters of the ionosphere. As a challenge, the time-series do not follow the same cadence, can contain missing values, and the sensors are moving (since they are satellites) - thus we do not have measurements for the same location across time nor for the same time across many locations.
Sparse Label Learning
This team investigates different strategies (random, passive, active) to obtain labels from a large pool of unlabeled image data. Given labels after the acquisition, they evaluate the impact of this more or less intelligently selected sparse set on the performance of various models for image classification. More precisely, the students assess the effect of selectively choosing labeled data on a model trained from scratch, a transfer learning model, and a state-of-the-art semi-supervised model that additionally has access to all unlabeled data.
Large Scale Graph ML
This team worked on one of the datasets from this year’s KDD Cup. The dataset is a full dump of Wikidata, a knowledge graph of 80M entities, 1.3k relation types and ~500M triples. The huge volume poses challenges for training models on GPU. This particularly holds for training graph-neural-network based models which require coherent subgraphs for batching, and efficiently obtaining represenative subgraphs is a non-trivial task.
Sustainability Mirror for Germany
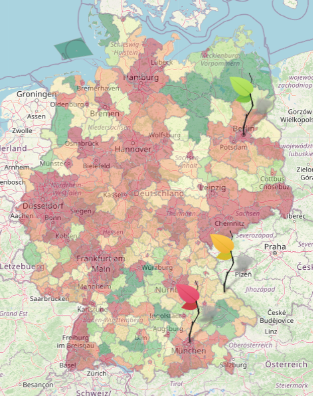
Environmental pollution is increasingly becoming a critical issue in the global community. Much of this pollution comes from human production and consumption of electricity. The main aim of this project, in cooperation with a large national energy provider, is therefore to try to raise awareness of these matters among the people. In this case the focus is purely set on Germany. The result displays a live map of Germany that shows the actual amount of CO2 emissions derived from the consumption and the production of energy on a county level. Moreover, this sustainability mirror shows details about the different sources of electricity.
Machine learning for earth observation gap filling, and gap filling validation
Clouds are a major and well-known issue when working with earth observation (EO) data. Dense clouds obstruct the earth surface and thus generate gaps in the data. This project revolved around the filling of those gaps. Specifically, the project consisted of two parts: First, machine learning (ML) possibilities for the purpose of gap filling were investigated and a recently proposed ML approach was applied to the problem and evaluated. The second part of the project was the development of a Python package to facilitate the validation of gap filling methods.
Climex - Predicting and Classifying European Weather Phenomena
The weather in Europe is mainly driven by high and low pressure systems and their constellations to each other. Typical constellations of high and low pressure systems are classified as atmospheric circulation patterns. The class “Tief Mitteleuropa” is known to occur rarely (~ 10 days/year), but when it does it often triggers extreme rainfall and floods in Central Europe. The more frequent class “Trog Mitteleuropa” with about 20 days/year is also related to heavy rainfall (Ustrnul & Danuta, 2001).
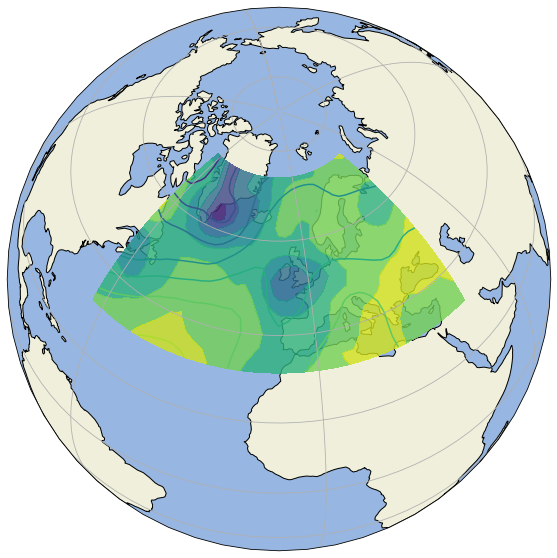
Investigating Satellite Imagery for Journalism
Together with a big media outlet, a team of students worked on using data obtainable from sattellite imagery for a journalistic project. The Goal of this Project was to create a tool that allows journalists to investigate several climate phenomena in a given area along with an analysis of their development over time. In the future, you might hear about the findings in the news!
Argument Mining for Peer-Reviewing
In this project, students applied techniques from Argument Mining on the new corpus of peer-reviews for scientific publications. Students implemented a pipeline for automatic identification of arguments in peer-reviews and demonstrated empirically the importance of arguments in the decision making process. The work was presented at AAAI-21.
Modeling of Earth’s Radiation Environment
The sun continually emits electrically charged particles. These particles get accelerated/decelerated by the earth’s magnetic field. High-energy particles can pose severe threats to satellite operations and affect electricity plants on the ground. In this project, which is a collaboration with LMU Geophysics, the students developed predictive models for proton intensities in space based on geomagnetic and solar activity indices. The models were applied to investigate the correlation between proton intensities and measurement corruptions of an existing spacecraft and forecast proton intensities to facilitate satellite operators to protect their instruments. The work appeared in the Astrophysical Journal.
Entity Alignment
Knowledge graphs (KGs) are a way to represent facts in a structured form that machines can efficiently process. There exist several large-scale common knowledge KGs, such as Wikidata or Google Knowledge Graph, but also more specialized ones, for instance, bio-medical ones, such as HetioNet. To combine information from different sources, entities from one graph have to be recognized in the other one, despite potentially additional labels/descriptions / associated data. This task is commonly referred to as Entity Alignment (EA). While humans can easily collect and combine information about an entity from different sources, the task remains challenging for Machine Learning methods.
In this project, the students investigated several state-of-the-art entity alignment methods based on Graph Neural Networks (GNNs) and Generate Adversarial Networks (GANs). They re-implemented the techniques in a common framework, compared the code published by the authors to the method described in the papers, and tried to reproduce the reported results.
Presentation
Generalization of Argument Mining Models
In the project, we studied the performance of several state-of-the-art argument detection models regarding the generalization capability across multiple argumentation-schemes.
Presentation
KDD-CUP 2020
In this project, we used data from the KDDCup 2020 to create a realistic taxi-dispatching simulation environment for Reinforcement Learning.
The data was analyzed, cleaned, and used to model the agent’s idle movement within the simulation and the taxi requests of passengers. Different kinds of policies were then implemented and evaluated, e.g., using Kuhn-Munkres and a value-based Reinforcement Learning algorithm.
Presentation
Contact-Averse Reinforcement Learning
In this project, we applied Multi-agent Reinforcement Learning techniques to teach agents to avoid contact with each other while at the same time trying to get to their target destination as quickly as possible. For that, a flexible grid environment with different agent observations and rewards was implemented. Then, we trained Deep Q-Learning agents to navigate the environments and avoid each other, comparing them to ignorant shortest-path agents as a baseline.
Presentation
Sustainability Mirror for European Cities
A team of 5 students, in cooperation with a large national energy provider, worked on a dashboard for various sustainability metrics for cities, making available data for air pollution, urbanization, renewable energy production and more. They combined multiple open data sources which are available for most major cities to provide metrics that are comparable across cities and can be updated automatically.
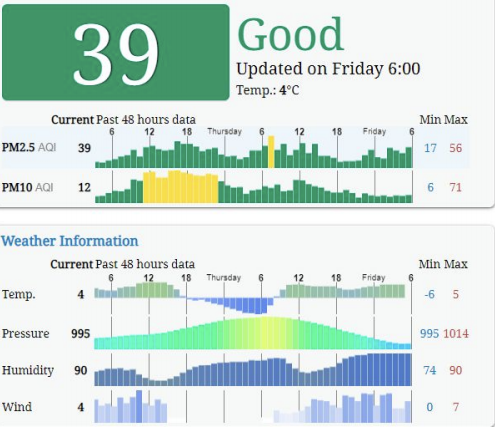
Energy Consumption Prediction Challenge
A team worked on the Energy Consumption Prediction Challenge and built a well-performing model along with an analytics dashboard that lets users predict energy for custom buildings. Github Page. In the second phase of the project the team built a webpage that allows users to predict the energy consumption of their buildings based on the model from the challenge.
IASS Social Sustainability Barometer
Another team built an interactive dashboard for the investigation of results from the IASS Social Sustainability Barometer in collaboration with the Institute for Advanced Sustainability Studies in Potsdam, Germany. The dashboard, built with R and shiny, shows the results of the social sustainability survey geographically and over time.
mlr3forecasting: Time Series Forecasting with Machine Learning
Students developed mlr3forecasting, an R package for time series forecasting with machine learning. Its goal is to facilitate time series forecasting, e.g., predicting global temperatures. It extends the popular machine learning framework mlr3.
Disaster Prediction Challenge
Students trained deep neural network models for the xview 2 disaster prediction challenge. The challenge’s goal is to find and localize damage from natural disasters on satellite images. The students built a model based on a U-Net architecture with a ResNet backbone and adaptive loss functions that was able to classify and localize damage types.

Anomaly Detection in X-Ray Images
In this project, the goal was to find anomalies in X-Ray images in a completely unsupervised fashion,
without using labeled data. This project was done in cooperation with Deepc, a start-up company founded
by LMU students.
Publication
Cross-Region Spatial Interpolation
In this project, the students dealt with spatial interpolation of weather information in mountain regions.
Our industry partner provided us with data from different regions. One of the main challenges in the project
is to learn a model that can be applied to new regions without the need for re-training.
Publication
KDD Cup
The students participated in a real Data Science challenge, where they had to compete against 800 Teams.
The goal of the challenge is to determine what is the best route for the user from different variants proposed
by a transportation app.
Poster,
Presentation
Ensemble Link Prediction for Knowledge Graphs
Knowledge graphs are a versatile tool to represent structured data used, for example, in the Wikidata
project or for the Google Knowledge Graph. Link prediction aims at predicting missing links in order to
enrich the knowledge base. This project’s focus is on combining different models into an ensemble in order
to exploit the individual models’ strengths.
Poster,
Presentation
Super Resolution
In object detection challenges, neural architectures often fail to detect small objects in images.
Through the recent developments in the research area of super-resolution, it is now possible to improve
quality of images. The students apply recently introduced Super Resolution techniques to improve object
detection performance.
Publication
Knowledge-based Argumentation
Argument mining is one of the hardest problems in Natural Language Processing. The main challenge is
that arguments are structurally similar to purely informative texts, and only differ semantically.
In this project, students utilized background information from knowledge graphs for better argument mining.
Poster,
Presentation
The Edmonton Tree Project
Aerial images yield a cost-efficient way to automatically generate census information about the
biodiversity in urban environments. In this project, the students developed a neural-network based object
detection and recognition method for registering and classifying trees in the city of Edmonton.
Poster,
Presentation
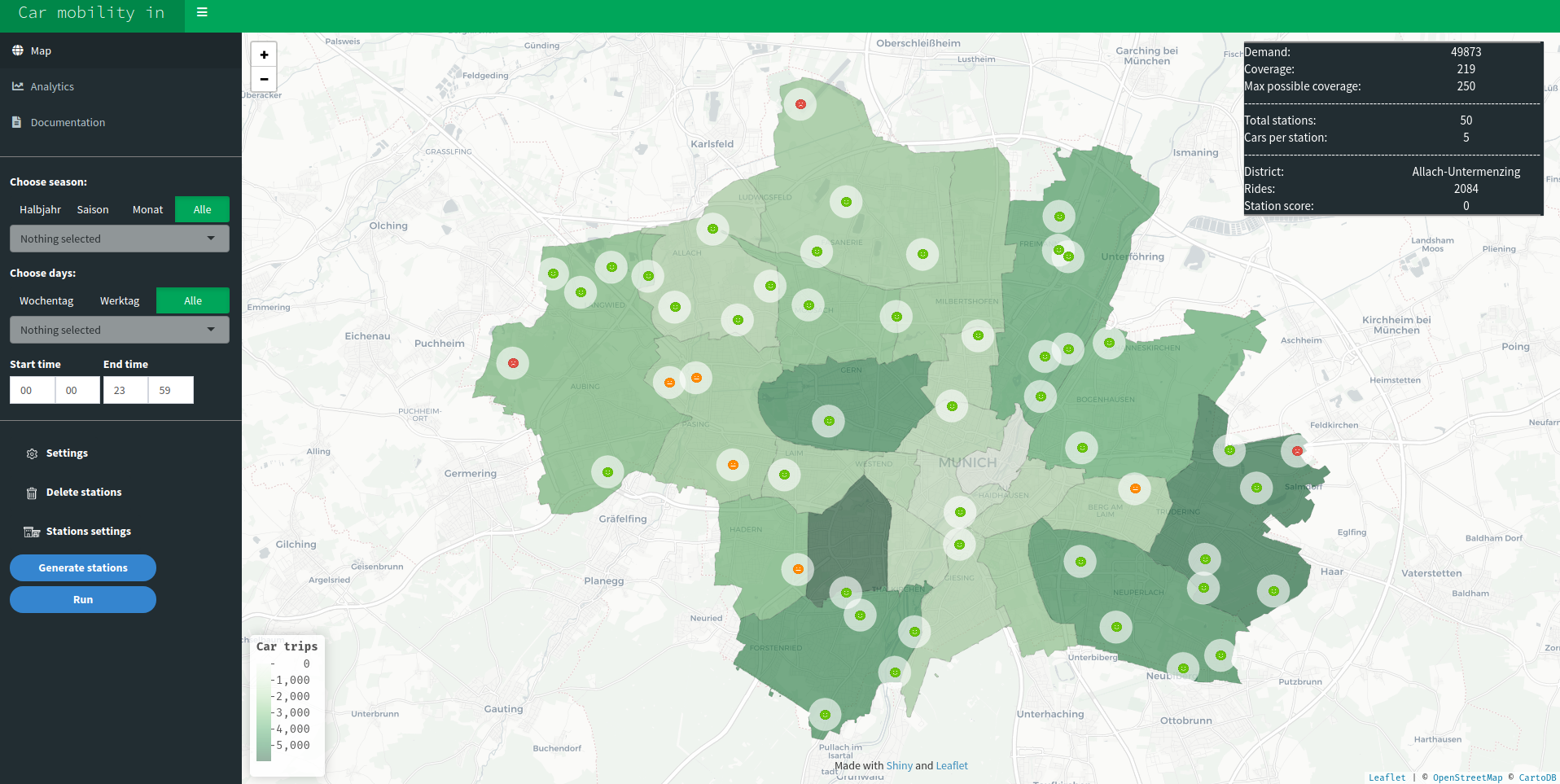
Accessibility to public transport in Munich
A group of students worked together with Green City EV, analyzing accessibility for residents of the city of Munich with respect to several modes of public transportation. As a result, students created an interactive dashboard that visualized access to public transportation on a borough-level and allowed for analyzing the influence of so-called ‘mobility stations’, hubs where public transport and private transport (carsharing, bikesharing) are brought together.
ggparty
A group of two students developed the open-source software ‘ggparty’. ggparty is a successful extension for the famous R package ‘ggplot2’, which allows for visualization of tree-structured models from the ‘partykit’ package. It provides the necessary tools to create clearly structured and highly customizable visualizations for tree-objects of the class ‘party’.
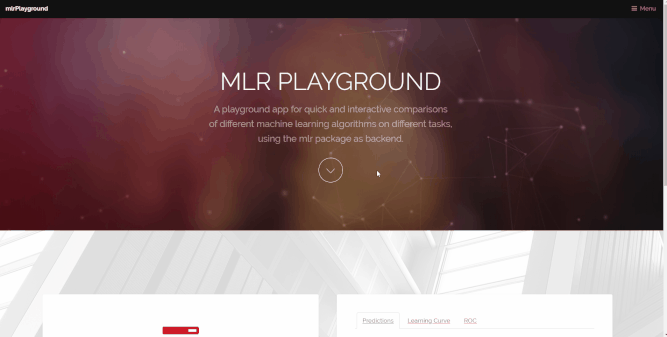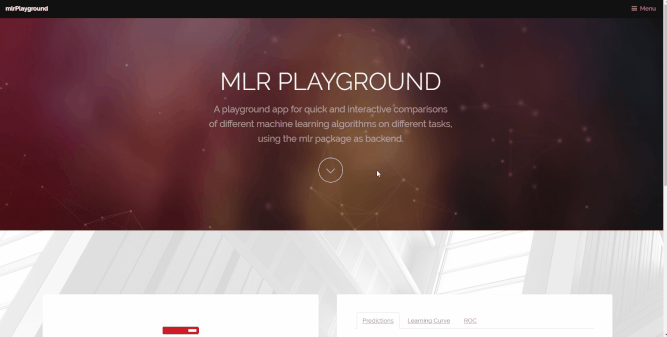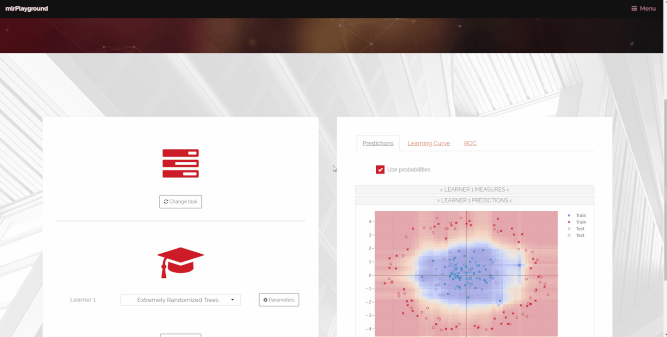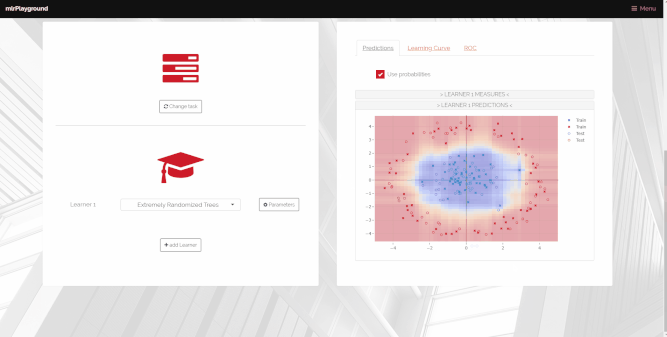
mlr playground
During teaching, it is often vital to be able to visualize properties of machine learning algorithms in order for students to be able to better understand their inner workings. Two students worked on the mlr playground, a webapp that lets the users ‘play’ with machine learning models for education. More information can be found on the project website.
A Labeling Tool for Object Detection with Active Learning
The goal of supervised learning is to learn a function that maps an input to an output based on input-output pairs.
At training time deep learning algorithms generally require a large number of labeled
training instances which are fairly rare in many domains. In practice, sets of labeled data are often
curated manually which is not only an unattractive job but also time-consuming and expensive.
In this project, which is an industry project commissioned by Harman International Inc., the students developed a labeling tool for object detection in image data which is additionally supported by active learning to reduce the amount of manual labeling effort. While training a deep object detection network in the background, the tool automatically selects unlabeled images that are, with respect to some evaluation metric, expected to improve the object detection network most. These images are shown to human labelers and subsequently used for training the network.
Is this movie worth to watch? Predicting the IMDb rating based on heterogeneous information
Have you ever seen a movie trailer and asked yourself whether you should spend the money watching this movie at the cinema? What are the decisive factors: the cast, the budget, the genre, the plot?
In this project, a group of students tackled this question by developing an AI approach to predict the average movies’ IMDb ratings. Via the web interface, the user can provide any information about a movie, e.g., the plot as text, the movie’s poster as an image file, and/or simply meta information such as actors, duration, genre, and so on. This information is collected, preprocessed, and given as input to the multi-component neural network in the backend which performs the actual regression for predicting the IMDb movie rating.
KDD Cup 2018 - Forecasting the Air Pollution
The KDD Cup is an annual competition in Data Mining and Knowledge Discovery organized by SIGKDD alongside the KDD conference.
In 2018, the participants were requested to predict the concentration of several air pollutants for London and Beijing. Given the historical measurement data from several air quality stations and weather data from meteorology stations, the task was to combine the weather forecast for the next 48 hours with this data to obtain a forecast of the air pollutants’ concentrations. Inspired by this competition, the group built a system that automatically retrieves the data, stores them in a database, and trains a variety of machine learning models on the collected data. Also, the process of evaluating the different models and their configurations is automated.
An appealing web interface allows exploring the data as well as the predictions of the models as well as their quality.
Explainable AI - Investigating the Activations within Deep Convolutional Networks
Despite the overwhelming success of deep convolutional networks in a broad variety of applications, most prominently image classification, their inner workings remain not fully understood. These networks comprise many layers, and each layer consists of a number of so-called channels. When fixing the layer and the channel, the values computed across different image locations are called activations and measure the presence of the learned feature. It is known that deeper layers learn more abstract and invariant features than early layers. In order to facilitate a better understanding of these features, the group built a system for explorative analysis of the activations of the famous Inception V3 model. Accessed via a web interface, the distribution of activation values faceted by class labels can be investigated.
Moreover, the tool shows a ranking of image patches that yielded the highest activation values, i.e. the patches that a feature responds to the most.
Automatic statistician for exploratory data analysis
In this project, the student team developed an R package AEDA that automatically analyzes data, streamlining manual steps of exploratory data analysis. A wide range of common tasks of data scientists is automated with this package: Basic data summaries, correlation analysis, cluster analysis, principal component analysis and more. All results are automatically compiled to a report.
Explaining machine learning predictions with game theory
In this project, the students developed an R package ShapleyR that implements Shapley values for explaining machine learning predictions. Shapley values are a method from game theory, which can also be used to understand the decision making of machine learning models better.
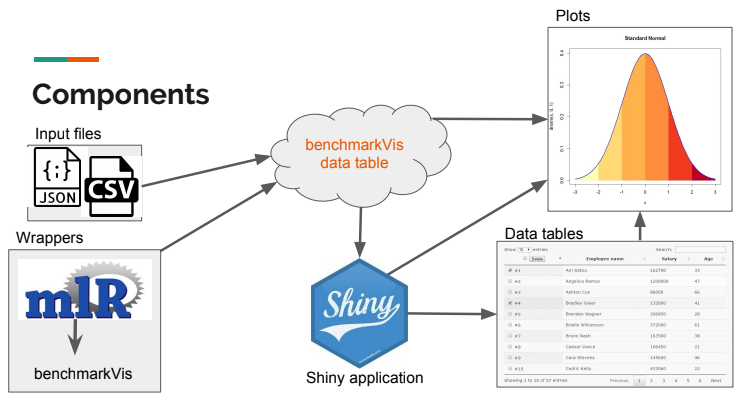
Interactive plots and tables for benchmarking results
The students developed an R package ‘benchmarkViz’ for comparing the results of benchmark studies. The project involved proposing a standard format in which arbitrary benchmark results, be it run time of algorithms or the performance of machine learning models, can be encoded and easily visualized.
Interactive plots for interpretation of global and local effects
The students implemented a dashboard for explaining machine learning models. The dashboard allows users to upload a model and automatically visualize it with different types of plots.